
Stop Building the Swiss Army Knife Integration Hub
Use this CIO-ready matrix to pick API, events, iPaaS or ESB, then unwind the “do-everything” layer safely.

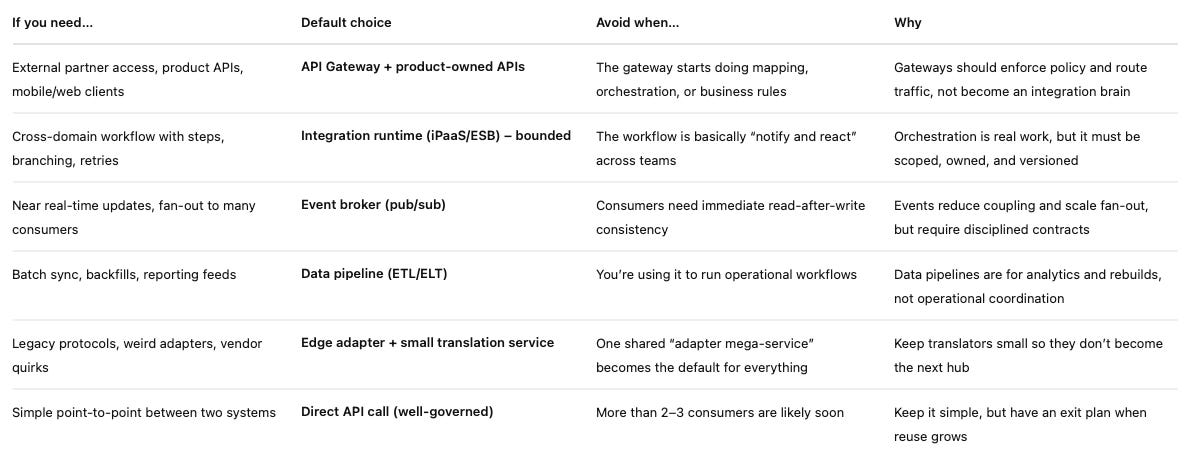
Integration decision matrix
Quick “Swiss Army knife” risk check
Tick 4+ and you’re in the danger zone:
One integration service owns routing and mapping and retries and auth and business rules
Every new project says: “Just add it to the hub”
Changes require a central team queue and a lot of coordination
A single deploy can break multiple unrelated domains
Teams can’t ship value without waiting on the hub
The hub keeps adding “optional fields” and “one endpoint for everything”
If you’re a CIO choosing API gateway vs iPaaS/ESB vs event broker, use the matrix above and make the call in 10 minutes. Then hold the line. The fastest way to slow delivery is letting one integration layer turn into the Swiss Army knife that “handles everything”. It feels tidy at first — one team, one platform, one place to plug things in. Then the queue forms. Every change needs a coordination meeting. One deploy breaks three unrelated journeys. Suddenly your integration layer isn’t enabling delivery; it’s rationing it. And the worst part? Domain ownership quietly slips away, because the real business logic ends up living in “the hub” instead of the teams that should own it.
The story: how the “helpful” integration hub became the choke point
It usually starts with good intentions. Two systems need to talk, the timeline is tight, and one team offers a “temporary” integration service to get things moving. It’s a sensible call: one connector, one mapping, one place to manage retries. It ships. People celebrate. Then the next project comes along and someone says, “Just run it through the integration hub; it’s already there.” And then the next one. Before long, the hub isn’t a shortcut; it’s the default.
Six months later, a small change goes out on a Thursday afternoon. It looks harmless. By Friday morning, five domains are dealing with failures they didn’t cause and can’t fix. Nobody wants to deploy without a war room. That’s when the nickname sticks: “The Octopus”, because everything runs through it, and when it thrashes, everyone gets dragged under.
The moment you realise you’re stuck
The hub becomes a queue, not a platform. Instead of teams owning their integrations, they file tickets and wait. Integration turns into a central dependency, and delivery slows to the speed of the busiest team.
What the Swiss Army knife integration anti-pattern looks like
You can spot it without reading a single line of code. It shows up in day-to-day behaviour, team habits, and the shape of the interfaces.
Interface bloat: “kitchen sink” endpoints appear in one API that tries to serve every consumer. Schemas grow into mega-objects with endless optional fields because “someone might need it later”.
Responsibility bloat: the same component starts enforcing security policy, transforming payloads, orchestrating multi-step workflows, and quietly embedding domain rules (“if VIP customer then…”).
Coupling bloat: every system’s release plan becomes dependent on the hub’s release cycle. Teams stop shipping independently because the integration layer is now the shared choke point.
Operational bloat: retries, dead-letter handling, monitoring dashboards, data fixes, and one-off scripts all pile into the same codebase. The hub becomes a production support tool as much as a runtime.
The net effect is predictable: changes feel risky, testing becomes expensive, and the blast radius grows. People start avoiding improvements because “touching the hub” is a career-limiting move.
Why it happens in enterprises (not because people are silly)
It’s usually a rational response to pressure. The pitch is simple: a central team will be faster and more consistent. Vendor platforms reinforce it by selling “do-everything” toolkits that make it easy to add one more connector, one more flow, one more rule. And without a clear split between gateway duties (policy and traffic management) and integration runtime duties (bounded orchestration and transformation), everything collapses into one place by default.
The real costs (and why they sneak up on you)
The Swiss Army knife hub doesn’t fail loudly on day one. It fails slowly, in ways that look like “just normal delivery friction” until you add it up.
Delivery: every change waits for the hub team. Even small tweaks carry a coordination tax: extra ceremonies, extra handovers, extra testing across journeys that don’t belong together. Your best engineers spend time negotiating the queue instead of shipping outcomes.
Reliability: the blast radius grows. One bad deploy, one misconfigured retry policy, one schema tweak, and suddenly multiple flows across unrelated domains degrade at once. Incidents become harder to isolate because the hub sits in the middle of everything.
Security and compliance: the hub becomes a privilege magnet. It needs secrets, tokens, elevated network access, and broad permissions “because it integrates with everything”. That’s exactly how you end up with a single component that’s both operationally critical and over-privileged.
Architecture drift: business rules leak into integration glue. The hub starts deciding things domains should own, and your domain boundaries get fuzzy. Over time, the real system behaviour lives in flows and mappings, not in the services that should be accountable.
A quick smell test
Ask two questions:
Can a domain ship value without changing the hub?
Do we have more than one way to integrate, and do we know why?
Root causes in plain English
This anti-pattern isn’t a tooling problem. It’s what happens when a few small decisions stack up and nobody draws a boundary early.
First, integration concerns get mixed with product decisions. Instead of domains owning what their data means and how it should change, the hub starts making those calls in mappings and flows. Second, “reuse” gets pushed too far. Someone introduces a mega canonical model to “standardise everything”, and now every team must contort their reality to fit one schema. That’s not reuse; that’s a shared constraint you’ll pay for forever.
Third, there’s no product thinking. The hub has users (engineering teams), but it rarely has a clear service promise, a catalogue of what it offers, or a roadmap that’s aligned with business priorities. Finally, a governance gap seals the deal: there are no lightweight rules that stop the hub from swallowing the next use case.
That’s the Swiss Army knife in a sentence: one interface trying to serve every use case and becoming worse for all of them.
The fix: split the problem into lanes
The way out is to stop arguing about “the right tool” and start agreeing on lanes. Each lane has a job, a boundary, and a failure mode you actively avoid. When you split the problem this way, you get a clean target state: teams can choose the right pattern for the job, ship independently, and you stop feeding the Octopus.
Lane 1: API gateway is for policy and proxy
Use the gateway for traffic management, not business logic:
AuthN/AuthZ, rate limits, WAF, routing, versioning, observability hooks
Avoid turning it into a “brain”. If the gateway is doing payload mapping, workflow branching, or domain decisions, it’s no longer a gateway; it’s a brittle integration service with a shiny badge.
Lane 2: Integration runtime is for bounded orchestration
This is where connectors and workflow steps belong:
Transformations, protocol translation, retries, and multi-step orchestration
The key rule: orchestration must have an owner and a domain boundary. If it’s “enterprise-wide glue”, you’re rebuilding the same anti-pattern with a different logo.
Lane 3: Event broker is for decoupling and fan-out
Use events to publish facts and let teams subscribe by need:
Publish “what happened”, not “how to do the job”
Keep event contracts lean and versioned, avoid fat events that try to carry the whole world. And be honest: event-driven isn’t magic. It needs discipline around contracts, idempotency, and observability.
Lane 4: Data pipelines are for analytics, not operational flow
Keep reporting and backfills in data plumbing, not runtime integration. Separate them so operational reliability and analytics flexibility don’t sabotage each other.
A practical 30/60/90-day plan to unwind the hub
You don’t fix a Swiss Army knife hub by “rewriting integration”. You fix it by stopping the bleeding, then moving work out in small, safe cuts. The goal in 90 days isn’t perfection, it’s momentum, lower risk, and a clear path where teams can ship without asking permission.
Days 0–30: Stabilise and put fences up
Start with a simple rule: no new “just add it to the hub” work unless it passes the decision matrix. That one move reduces future debt straight away. Next, make the hub visible. Pick the critical flows (the ones that wake people up at 2 am) and create one dashboard per flow. Add basic SLOs so you can say what “good” looks like. Then improve change safety: introduce contract tests for the top integrations and agree on a basic rollback plan. If you can’t roll back quickly, you’ll never move fast safely.
Days 31–60: Split by ownership, not by technology
Identify the top five flows by business criticality and map who should own the behaviour. Then carve out thin adapters at the edge and move domain rules back into the services that own the outcomes. This is the big mindset shift: you’re not “modernising integration”, you’re restoring accountability. Introduce a lightweight integration catalogue: what exists, who owns it, how changes happen, and where the contracts live.
Days 61–90: Migrate, retire, and measure
Replace one end-to-end workflow with either events or bounded orchestration, then retire what it replaced. Decommission at least one hub capability, a connector, a mega mapping, or a reporting job. Finally, track the metrics that prove it’s working: lead time, incident rate, blast radius, and deployment frequency.
Governance that prevents the next Swiss Army knife
Governance only works if it’s light enough to survive contact with delivery. You don’t need a committee for every integration; you need a few clear rules that make the right choice the easy choice.
Start with a one-page integration decision record. It should capture two things: why this pattern (API, runtime, events, or data pipeline) and who owns it end-to-end. No owner, no build. Next, publish simple guardrails: the gateway does policy and proxy, the integration runtime does bounded orchestration, and events are for fan-out. Make these rules visible and repeat them until they become habit.
Then lock in a practical definition of done: contracts are versioned, observability exists at the flow level, and ownership is explicit (including who’s on the hook when it breaks). Finally, use AI where it helps: let it draft mappings, generate contract tests, and propose runbooks, but keep human approval in the loop. That gives you speed without handing control to the tool or the hub.
“The Octopus” wasn’t evil. It was overloaded to be a gateway, an orchestrator, a translator, a rules engine, and a support console all at once. Once you see that, the fix becomes clear: this is less about swapping tools and more about restoring ownership and boundaries so teams can ship safely without a central choke point.
If you want more run-it-on-Monday architecture and governance playbooks (no fluff), subscribe to my newsletter.